This post was written by Rich Bosomworth.

Discover the acclaimed Team Guides for Software – practical books on operability, business metrics, testability, releasability
The recent AWS service outage has renewed interest for enhanced resilience, particularly multi-region design. In this series of posts we explore considerations when designing and deploying multi-region architectures in AWS. Working knowledge of AWS is assumed, along with an awareness of n-tier architectures and DNS concepts.
The first question you should ask is, do you really need multi-region resilience? Or could your business continuity levels accommodate a potential half-day service disruption? (As was the case with the February 2017 AWS S3 outage).
The core reasons for this question are two fold:
Multi-region cloud architecture can be expensive.
Multi-region cloud architecture can be complex.
We say can be, as there are varying levels of multi-region design, depending on how much resilience you would like to employ. There are also caveats around what is and isn’t actually possible with regard to the technology involved. For example, although AWS offer multi-region read-replicas from their RDS database service, there are limitations with data transfer speeds across wide area networks. This means that an asynchronous write to a remote region will incur higher degrees of latency than to adjacent zones. As such, remote region read-replicas could not be used as a live source of application data reads. They are intended to be put in place only for purposes of failover, and/or replication with regard to disaster recovery.
The second question is, failover or resilience? i.e. are you looking at total resilience for your infrastructure? With a comprehensive fail-safe multi-region design accommodating a full region outage with no down time? Or, are you happy with manual launch scenarios requiring degrees of scale-up?
The expectations and requirements of the business are a core factor. If you have a relatively static WordPress based website or blog, with infrequent updates and a geo-specific audience, then to have a costly global resource mirror around several regions would seem overkill.
With these questions in mind, let’s take a look at our first scenario.
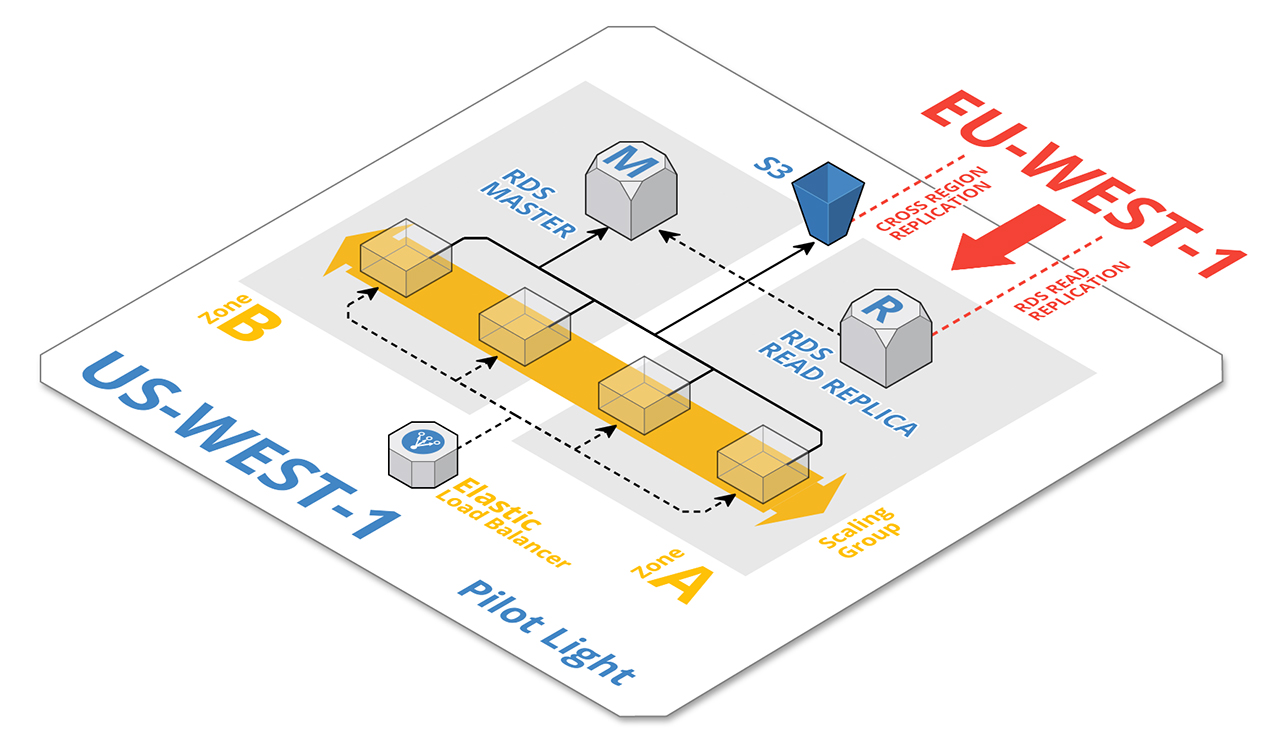
Pilot Light #1
With pilot light failover, a minimum of core services are kept alight in a secondary region. In the majority of cases this would involve a low-resource read replica of the database.
Method
In the event of a primary region outage, the following manual steps are taken in the secondary region to restore service functionality.
- The RDS DB RR is promoted to master, the instance size increased and a DB slave created.
- Supporting services (i.e. ec2 instances, load balancers etc) are created/scaled and primary DNS entries updated, re-routing traffic to services in the new region.
- Static application code is then deployed to the new infrastructure.
NOTES:
- An RDS DB RR pilot light scenario is only suitable for architectures employing a stateless application front end.
- It is advisable to use a Route53 CNAME DNS record for the RDS DB endpoint and reference this from within the application, updating the record post-failover to point at the new RDS master. By adopting this method the application code does not have to be updated when it is redeployed.
Pilot Light #2
Scenario 2 extends the RDS DB RR concept to include static data held in AWS S3, with buckets configured for cross-region replication (Fig:1).

Fig:1
S3 cross-region replication does exactly what it says, i.e. replicates uploaded files to a chosen bucket in an alternate region. It is configured on a per-bucket basis from within the S3 console (Fig:2).
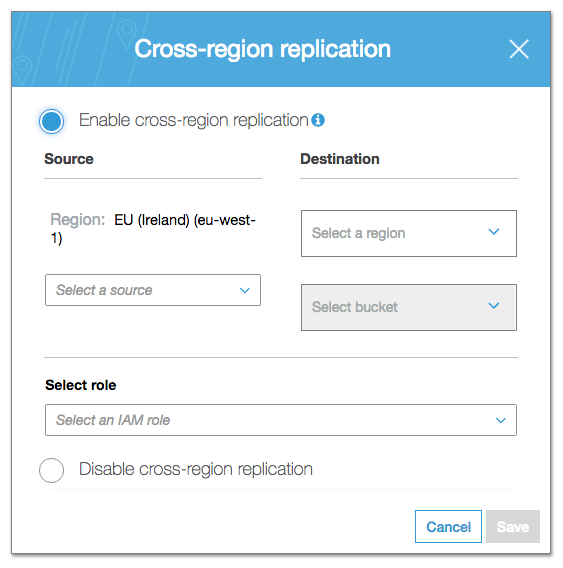
Fig:2
Method
As with Pilot Light #1, in the event of a primary region outage the RDS DB RR in the secondary region would be promoted to master, the instance size increased and a DB slave created. Supporting services (i.e. ec2 instances, load balancers etc) are created/scaled, however the s3 component adds extra levels of complexity and restrictions for DNS failover. This is because s3 bucket names have to be globally unique. It is not possible to create a bucket with the same name in another region (Fig:3).
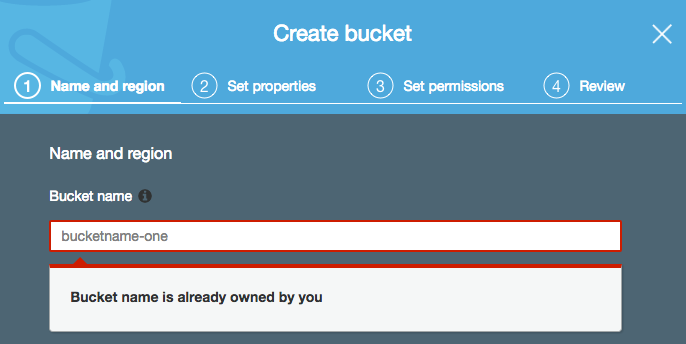
Fig:3
So, although Route53 DNS can facilitate failover to a secondary record set from a failed health check, the following configuration using the same bucket name in different regions would not be possible:
http://s3-eu-west-1.amazonaws.com/bucketname-one/image1.jpg http://s3-us-west-1.amazonaws.com/bucketname-one/image1.jpg
Instead, the buckets would have to be created using individually unique names across regions (Fig:4):
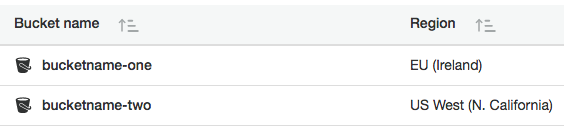
Fig:4
With corresponding DNS as follows:
http://s3-eu-west-1.amazonaws.com/bucketname-one/image1.jpg http://s3-us-west-1.amazonaws.com/bucketname-two/image1.jpg
CNAME failover using region identifiers would therefore not be viable. Although the CNAME section would be valid, the following bucketname identifier would be different. As such, code would need to be updated with the revised bucket endpoints prior to deployment. There are methods for s3 failover using mapped Cloudfront distributions coupled with R53 DNS health-checks, however such configurations are more workarounds than solid supported processes.
In light of recent events, it is expected that AWS will make moves to implement more accessible methods of region failover for s3. A good place to start could be with intelligent failover for Cloudfront multi-origin distributions.
In the next post we shall take a look at configuration options for Warm Standby. This is a scenario with a full set of active resources running in a secondary region, including the application, but in a reduced capacity ready for scale.
