
This post was written by Matthew Skelton co-author of Team Guide to Software Operability.
Deployability is now a first-class concern for databases, and there are several technical choices (conscious and accidental) which band together to block the deployability of databases. Can we improve database deployability and enable true Continuous Delivery for our software systems? Of course we can, but first we have to see the problems.
Until recently, the way in which software components (including databases) were deployed was not a primary consideration for most teams, but the rise of automated, programmable infrastructure, and powerful practices such as Continuous Delivery, has changed that. The ability to deploy rapidly, reliably, regularly, and repeatedly is now crucial for every aspect of our software.
This is part 1 of a 7-part series on removing blockers to Database Lifecycle Management that was initially published as an article on Simple Talk (and appearing here with permission):
- Minimize changes in Production
- Reduce accidental complexity
- Archive, distinguish, and split data
- Name things transparently
- Source Business Intelligence from a data warehouse
- Value more highly the need for change
- Avoid Production-only tooling and config where possible
The original article is Common database deployment blockers and Continuous Delivery headaches
Deployability and Continuous Delivery
The value of Continuous Delivery – regular, rapid, reliable and controlled delivery of working software systems into Production – is becoming increasingly apparent. Not only do your users see results and new features more quickly (thus making for a happier management team), but the shorter feedback cycle vastly increases your ability to learn about and improve the software system as a whole, reducing bug-fixing and ‘firefighting’. Everyone wins!
However, in order to sustain this high rate of controlled change, the component parts must be easy and quick to deploy and verify, and the simplicity and speed of deployment (and post-deployment verification) are measures of their “deployability”. In short, it’s now essential to be able to deploy database schemas, objects, code, procedures, reference data, and a representative sample of dynamic data as easily as deploying an OS package or a web application.
Thankfully, the tools and techniques for achieving this are already largely known, although in some cases we may need to change how we use our databases in order to take full advantage of them.
What prevents deployability for databases?
Several ‘forces’ act against databases to make them increasingly undeployable over time: the complexity of database-internal logic; complexity of cross-application dependencies; sheer size (data volume); risk (or more accurately, perception of risk); and Production-specific tooling and configuration. None of these is necessarily a critical issue in itself, and most will be recognised by experienced DBAs. However, taken together, they will bring your deployment to its knees.
As a first step, we need to acknowledge that many databases – particularly those ingesting and supplying transactional data from live applications – need to be treated somewhat differently in Continuous Delivery from most other parts of the application and infrastructure estate, and this is partly why their deployability blockers might not be obvious at first.
Many of these problems aren’t at all unique to databases, but if you’re a DBA you’ll almost certainly recognise and have worked around them individually for separate reasons. However, even though these problems may seem disconnected, taken in combination, they are sure-fire ways of making your databases painful to deploy: the whole is greater than the sum of the parts.
By the same token, the ‘remedies’ described here may well be practices you’ve put into place before but, taken together, they’ll form the backbone of a painless database release process. Of course, none of these changes or steps are “free”, because refactoring is hard (as is explaining to the Business Intelligence team that they can’t have access to the production database anymore). If you want to optimise for database deployability – and you should! – then here are some things to tackle right away.
1. Flow of Production-originated data vs. everything else
Let’s start with a problem that actually IS fairly special to databases. Our applications, middleware, infrastructure, database schemas, reference data, and even cloud hosting ‘fabric’ can and should now all be defined as code, and flowed down a deployment pipeline from development towards Production, with significant automated (and possibly some manual) testing on the way. In effect, like salmon swimming upstream, Production-originated data needs to go ‘against the flow’ of changes and user requirements, which all flow ‘downstream’. However, too often this pattern of ‘Production first’ is also used for changes to schemas, reference data, and database logic, leading to ‘drift’ between the Production database and versions used by development and test teams. As you can guess (and are probably aware from painful experience), that’s going to block your deployments.
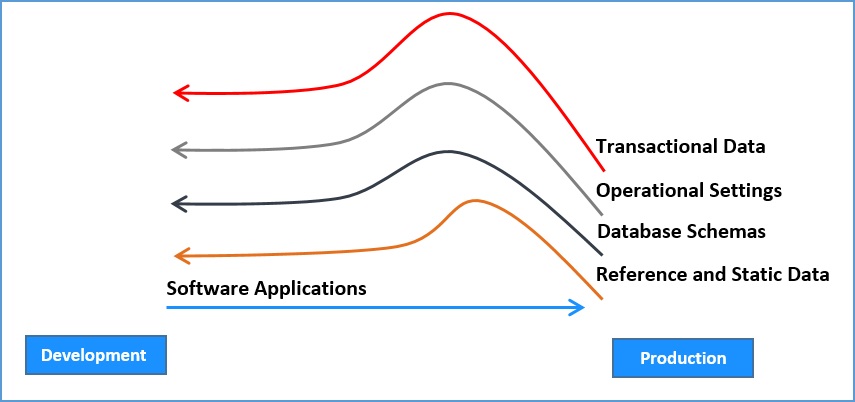
Remedy: Minimize changes in Production
One way we can improve the deployability of databases is to separate the database changes that should flow downstream (with other code changes) from the data which cannot. Ideally, the only database changes that should be made ‘in Production’ are changes to live data, and reference data should change in development and flow down. The addition of new indexes and other performance tuning should be made in a pre-Live environment using recent live data and traffic replay techniques.
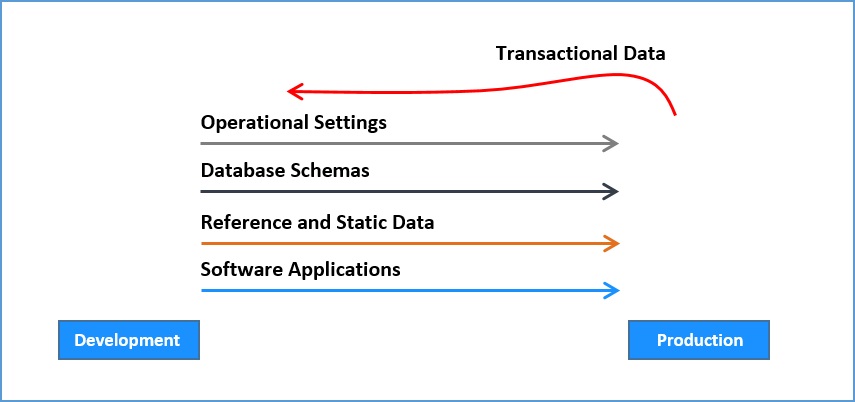
By reducing the ‘specialness’ of Production down to its live data, we can increase the amount of testing possible in upstream environments. This will increase confidence in database changes, encouraging a higher rate of change, and in turn a reduced fear of database deployment (not to mention reducing surprise fire-fighting). This also improves the team’s ability to track changes and roll-back changes that don’t go according to plan.
1 >>

