This post was written by Matthew Skelton co-author of Team Guide to Software Operability.
`Deployability is now a first-class concern for databases, and there are several technical choices (conscious and accidental) which band together to block the deployability of databases. Can we improve database deployability and enable true Continuous Delivery for our software systems? Of course we can, but first we have to see the problems.
Until recently, the way in which software components (including databases) were deployed was not a primary consideration for most teams, but the rise of automated, programmable infrastructure, and powerful practices such as Continuous Delivery, has changed that. The ability to deploy rapidly, reliably, regularly, and repeatedly is now crucial for every aspect of our software.
This is part 2 of a 7-part series on removing blockers to Database Lifecycle Management that was initially published as an article on Simple Talk (and appearing here with permission):
- Minimize changes in Production
- Reduce accidental complexity
- Archive, distinguish, and split data
- Name things transparently
- Source Business Intelligence from a data warehouse
- Value more highly the need for change
- Avoid Production-only tooling and config where possible
The original article is Common database deployment blockers and Continuous Delivery headaches
Accidental size and complexity
I’ve seen several almost identical cases where successful organisations, operating with an increasing online presence since around 1999, have reached a point in 2014 where their core database effectively dictates the rate of change of their systems. These organisations all have (or had) a large, central database that started out small and gradually grew to become highly unwieldy, apparently risky to change, and difficult to deploy.

The database was seen as the ‘single source of truth’ and allowed to grow, not only in terms of the accretion of live records, indexes and views, but also in terms of the applications that depended upon it directly. Given that they’re all now at varying stages of adopting Continuous Delivery, this presents them with a serious challenge!
Early on, the presence of all data in the same place was great for rapid development, but over time the complexity of the data required specialist skills to maintain, and changes became more and more painful and risky as multiple teams vied to make changes to suit their application’s view of the business domain. This typically leads to highly expensive or complicated database technology in order to manage the database, perhaps available only in Production/Live (and I’ll come to that on part 7 of this series), and other systems in the business suffer as budgets and resources are suddenly decimated. Sound familiar?

Of course, some of this is irreducible once your organisation or application reaches a certain scale, but often it stems from opaque legacy processes, organisational red-tape, or just inexperience. In any case, the additional complexity makes it difficult for individuals or teams to understand the database, and so – particularly when diagnosing a failed deployment – makes database deployment difficult.
Remedy: Reduce accidental complexity
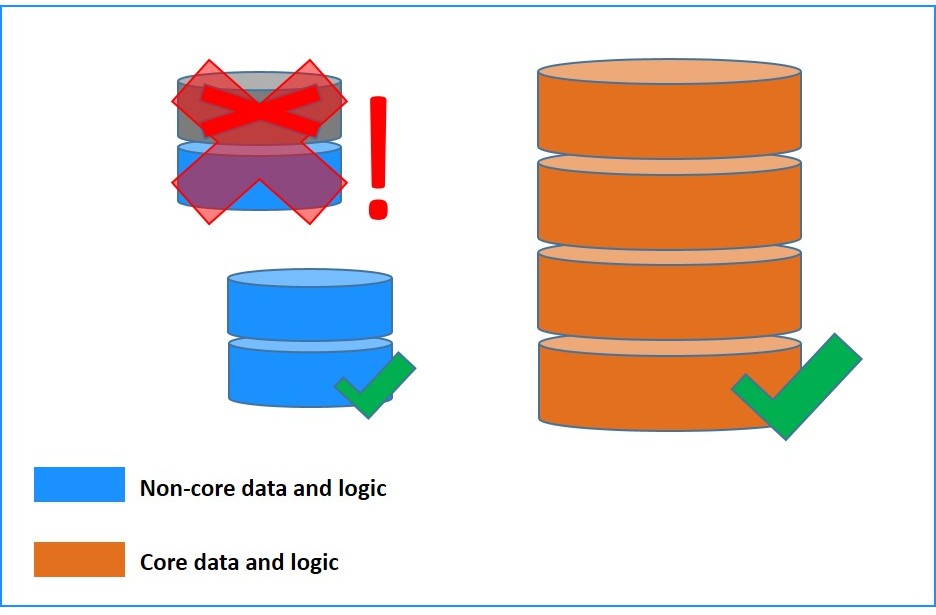
In short, the smaller and less complex an individual database, the easier it becomes to deploy. As a general rule, I’d argue that it’s always preferable to reduce the internal complexity of any system, especially any unnecessary complexity, down to just what is truly irreducible. Complexity in systems generally scales geometrically with number of interrelationships, not linearly – so keeping the number of interrelationships fairly low is a useful engineering maxim if we want to build human-comprehensible systems.

Moving non-core data and logic out of the main database and into separate databases helps to make the core database less complex, and more amenable to human understanding. This both reduces fear around database changes and reduces the number of possible failure states for database changes! Reducing the size of databases by taking out accidental data then has the double benefit of reducing the hardware requirements to run the databases (potentially even allowing a technology change), and allowing more rapid and frequent upstream testing.

But how do you decide where to split the data? I’m glad you asked…

