
This post was written by Matthew Skelton co-author of Team Guide to Software Operability.
Deployability is now a first-class concern for databases, and there are several technical choices (conscious and accidental) which band together to block the deployability of databases. Can we improve database deployability and enable true Continuous Delivery for our software systems? Of course we can, but first we have to see the problems.
Until recently, the way in which software components (including databases) were deployed was not a primary consideration for most teams, but the rise of automated, programmable infrastructure, and powerful practices such as Continuous Delivery, has changed that. The ability to deploy rapidly, reliably, regularly, and repeatedly is now crucial for every aspect of our software.
This is part 7 of a 7-part series on removing blockers to Database Lifecycle Management that was initially published as an article on Simple Talk (and appearing here with permission):
- Minimize changes in Production
- Reduce accidental complexity
- Archive, distinguish, and split data
- Name things transparently
- Source Business Intelligence from a data warehouse
- Value more highly the need for change
- Avoid Production-only tooling and config where possible
The original article is Common database deployment blockers and Continuous Delivery headaches
Production-only technology and configurations
Special Production-only database technologies, configurations (e.g. linked server mappings), and routines all work against database deployability. Even if the volumes of Production data cannot feasibly be re-created in upstream environments, the database technologies, configurations, and features should be – at the very least in a Pre-Production environment. I’d even go so far as to say that if the cost of licenses for upstream environments would be prohibitive, then you should seriously consider an alternative technology because the hidden costs of a ‘unique’ database set-up in Production are huge.
Some of this might stem from one of sheer data volume problems we’ve already discussed, which could be fixed in a few different ways, but it might also be down to resourcing, organisational politics, or some other set of priorities that don’t rate ‘the ability to release software’ as highly as they should.
One organisation which I recently worked with moved to Oracle Exadata for its live transactional database. The improvement in query speeds was astonishing, and the built-in diagnostic tooling very useful. However, the Exadata machines were for Production and Pre-Production only (due to cost) and, because Exadata worked so differently from the versions of Oracle in upstream environments, it was difficult to predict the query behaviour before deployment to Pre-Prod, leading to uncertainty about performance. Furthermore, the ‘developer’ version of the database, Oracle XE, only allowed a single schema, significantly hampering useful automated testing in deployment pipelines. The presence of the high-speed Exadata machine also meant that requests from developers and testers to improve the database to enable better development and testing tended to be ignored because “Exadata will handle it fine in Production”, leading to ever-slower integration tests and development speed!
If you can’t test or develop every element of your software – including the database – in an environment that simulates Production, then how can you possibly have confidence that your software will deploy, let alone work as expected? Production-only setups work against database deployability by ignoring upstream development and testing requirements, meaning that high rates of failed deployments and buggy releases are effectively guaranteed.
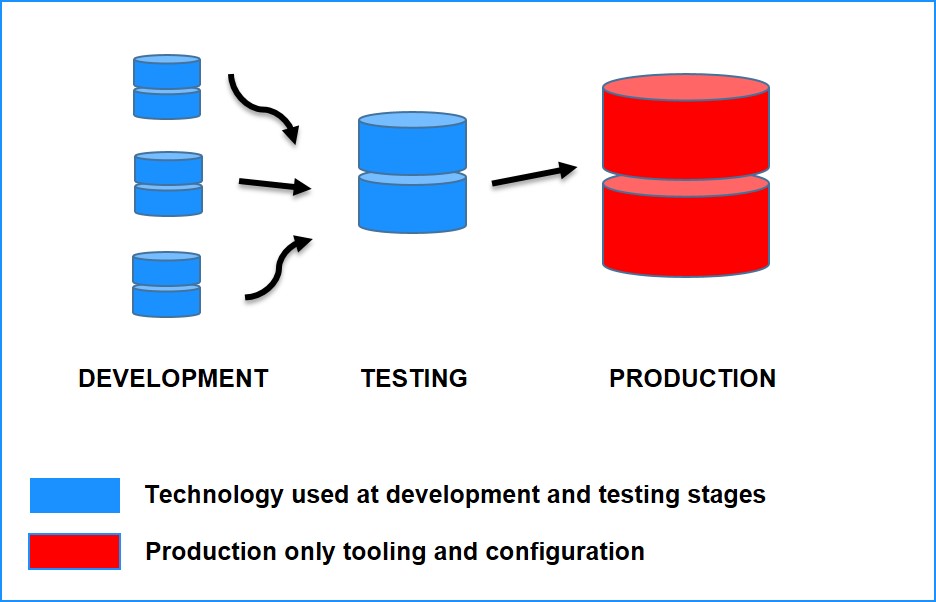
Remedy: Avoid Production-only tooling and config where possible
We should aim to keep the live transactional databases fairly small and simple, moving rarely-requested data to a warehouse, and allow the transactional database to run on less specialised technology. Using the same technology and configuration across environments reduces uncertainty and fear within teams, aids collaboration and diagnosis, and even helps to keep data size and complexity low, all of which help to make the databases as deployable as possible.
For large data warehouses, expensive database technology is often needed purely for performance reasons. However, for live transactional databases that need rapid and reliable changes and deployments, it is usually better overall to use technologies that can be present in all environments from the developers’ laptops, through Test and Pre-Production, all the way to the Production racks.

Wrapping up
None of the issues explored here would, by themselves, necessarily prevent rapid and reliable database deployments, but taken together these issues present significant blockers to database deployability. At the same time, none of these issues are necessarily new or unique to databases, but hopefully by considering them as a related set you can see how significant their combined impact can be. To address them individually perhaps doesn’t seem too challenging, but to tackle deployability requires close, effective collaboration between developers, DBAs, and operations teams to achieve the right balance between rapid deployment and access to data.
<< 7

