
What follows is a guest post from Fiercely, a software consultancy based in Coimbra, Portugal.
After a great presentation at IPEXPO Europe on “Continuous Delivery Anti-patterns from the wild” by Matthew Skelton, we quickly drew parallels with our own work and experiences here at Fiercely.
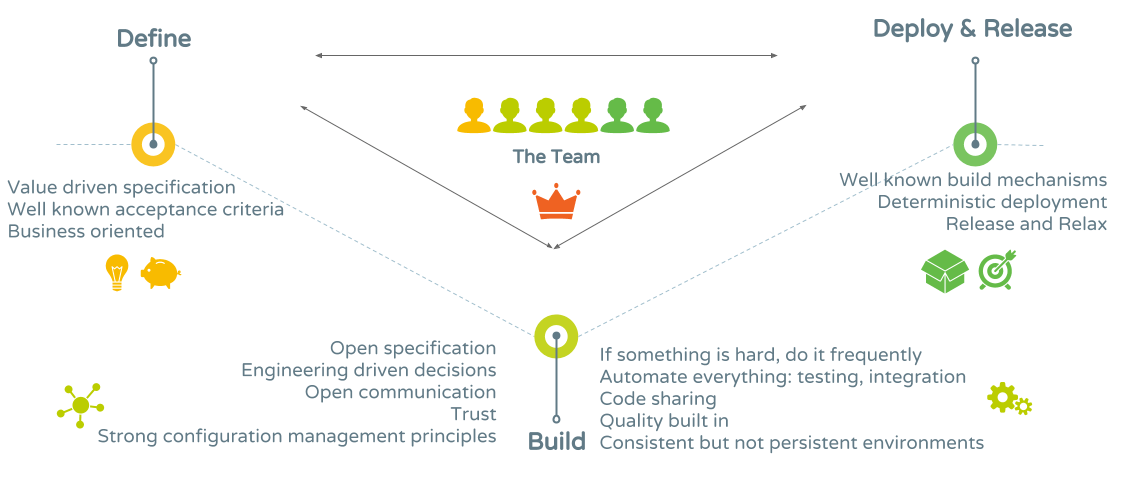
More importantly, we got to thinking on how we usually address these anti-patterns. In this post we would like to focus on two of them:
“No investment in build & deployment” is a major problem in any organization that wants to build and deliver software in a more reliable and predictable manner. Especially in the case of large “legacy” systems, we often find the need for “magical steps”, only known to some team members, in order to build the system. Moreover, the team has “comfortably” agreed to live with the burden they impose.
Most organizations don’t account for how much time these “magic steps” actually take. When you only deploy twice a year, that time is probably negligible. But what if we account for all the manual testing and deployment across several different environments, the release branching (and subsequent “merge hell”), and the repetitive deployment “babysitting”? How much time are we really spending/wasting after all?
Typically, lack of investment only becomes evident either when organizations want to go faster (e.g. more deployments, shorter release cycles) or a major refactoring (e.g. underlying platform major version update) is needed. In these cases, people begin to wonder how they can work differently, because the pain will be felt more frequently.
At one of our clients we had to help address this exact problem. The development team had a fairly large system built on top of a 3D engine and needed to stabilize their build and deploy pipeline. Their top issues were only able to build from one specific machine and they relied on a very slow and time-consuming process that required full-time commitment by one developer. This made it impossible to build the software continuously. So we invested in creating a build pipeline that would run independently on every merge request, across all necessary repositories, whilst also having producing deployable assets, on a daily basis. A developer now only needs to worry about their application changes and not the building and distribution of deployable assets. This also had a positive side-effect of clarifying dependencies and synchronization efforts for teams that need these deployable assets for exploratory testing and demonstration purposes.
We also had real-world examples of the second anti-pattern, “Just plug in a deployment pipeline”. Again, in software organizations with legacy applications, you cannot just plug in a new shiny pipeline and expect the deployment process to improve instantaneously. The system itself might not be ready. If there are not enough unit tests, and/or no functional specifications and validations, what is the gain? In these situations, we need to address these other issues as well: help the team re-architect the system where needed, stabilizing code into components and then making use of a well known and deterministic build and deploy process.
We were confronted with this anti-pattern in a client with a large legacy code base, nearly zero unit tests and very high-level specifications, based on natural language, impossible to automate. We had to, first of all, help them re-architect their system. After an initial analysis, the team decided that re-architecting would not be sufficient and therefore decided to start a fresh new project, backed up by new needs from business.
Upon further reflection on these anti-patterns, we’d like to suggest another one that we have felt often across multiple clients:
Business and development are just as far apart as development and operations
Business and technical staff have (de-)evolved into completely siloed functions, communicating almost always via email, specification documents or specification tools. The outcome of this way of working is a finger pointing culture. And this is the greatest shift that must occur in any organization wanting to build better, faster and cheaper software: changing the culture. Business and technical staff need to work together and collaborate, not “throw artefacts” over the wall to the other side.
In order to address this anti-pattern, we first need to re-define team configurations, integrating traditional business analysts in the team. This person must also be committed to delivering working software. Just as the developer’s job is not done when the source code compiles, the business analyst’s job is not done when the requirements specification is approved.

Software needs to be delivered. Software needs to be used.
Real users will tell us if the software fulfills their requirements. Everyone needs to be involved and actively listening in on this feedback loop. This also became the most important goal to monitor for the team: delivering working software. The communication between these two job profiles must be based on a continuous conversation about the acceptance criteria. The business analyst does not simply specify these criteria, he or she needs to explain it and evolve it as the conversation with developers occurs.
Applying this kind of transformation has proven to be very successful across clients. Teams composed of business and technical profiles aim at delivering software and not just “making their individual job contribution”.
